
Institute for Intelligent Computing, Alibaba Group

Introducing EMO, an advanced framework for generating expressive portrait videos driven by audio input. By simply providing a reference image along with vocal audio (for instance, speaking or singing), our innovative method can create engaging vocal avatar videos. These videos not only showcase expressive facial expressions but also adapt head poses dynamically. Importantly, the duration of the videos can be scaled according to the length of the input audio.
Methodology
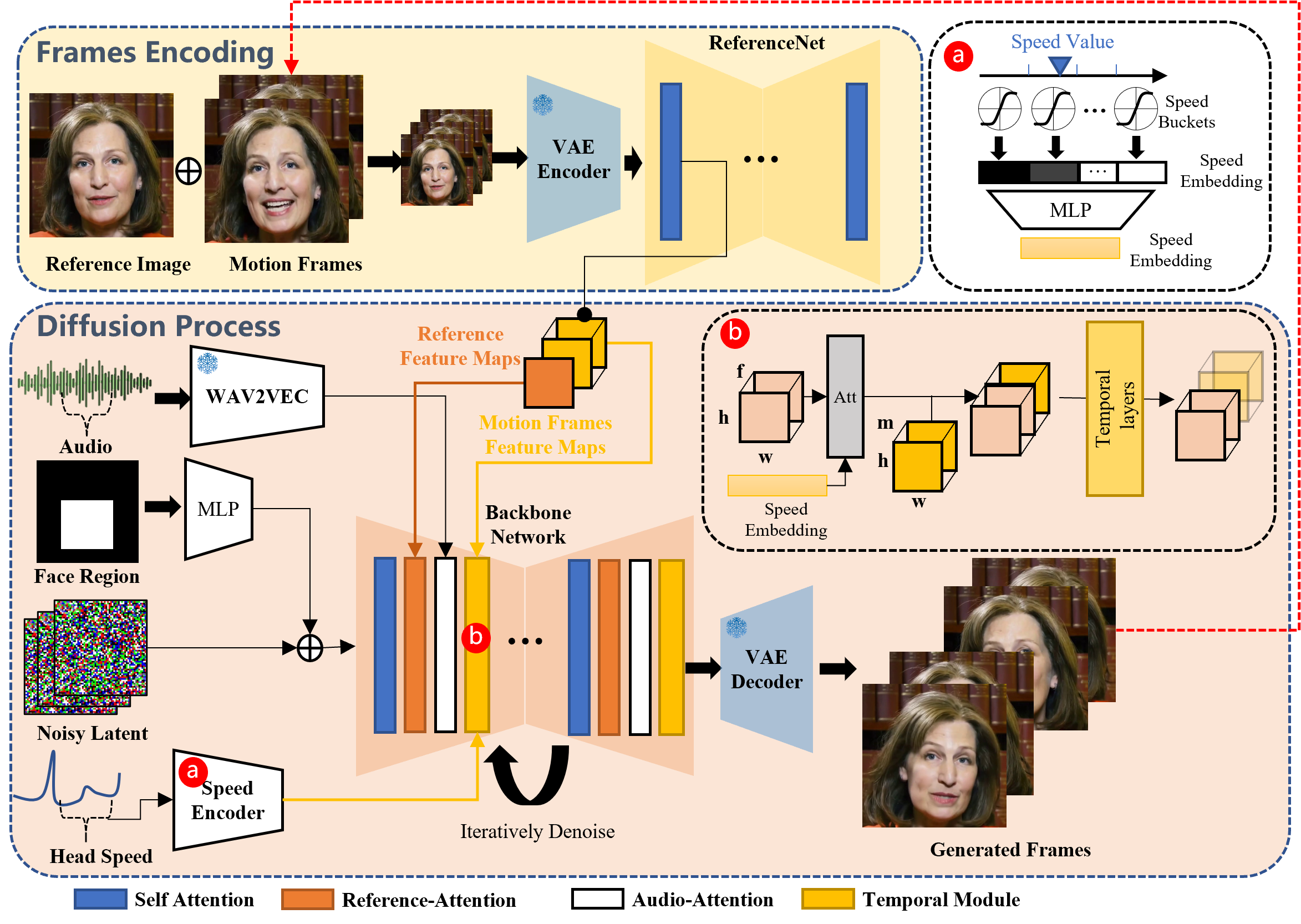
The framework consists of two primary stages:
- Frames Encoding: This initial stage utilizes the ReferenceNet to extract features from both the reference image and motion frames.
- Diffusion Process: In this stage, a pretrained audio encoder processes the audio embedding. This stage integrates a facial region mask with multi-frame noise to govern the generation of facial imagery. Following this, the Backbone Network is employed for denoising operations, implementing two types of attention mechanisms: Reference-Attention and Audio-Attention. These mechanisms play a vital role in maintaining the character’s identity and ensuring that the character’s movements are modulated appropriately. Additionally, Temporal Modules adjust the velocity of motion, allowing for fluidity and realism.
Various Generated Videos
Singing 🎶
Make Portrait Sing
Providing a single character image along with vocal audio (such as a singing track) allows our method to produce vibrant vocal avatar videos. These videos are characterized by expressive facial expressions and a range of head poses, with durations stretching according to the length of the input audio. The method effectively preserves character identities during longer durations.
Character: AI Mona Lisa generated by dreamshaper XL
Vocal Source: Miley Cyrus – Flowers. Covered by YUQI
Character: AI Lady from SORA
Vocal Source: Dua Lipa – Don’t Start Now
Different Languages & Portrait Styles 🌍
This method excels in supporting songs in diverse languages while animating various portrait styles. By intuitively recognizing tonal variations in the audio, it creates dynamic, expression-rich avatars.
Character: AI Girl generated by ChilloutMix
Vocal Source: David Tao – Melody. Covered by NINGNING (mandarin)
Character: AI Ymir from AnyLora & Ymir Fritz Adult
Vocal Source: 『衝撃』Music Video【TVアニメ「進撃の巨人」The Final Season エンディングテーマ曲】 (Japanese)
Character: Leslie Cheung Kwok Wing
Vocal Source: Eason Chan – Unconditional. Covered by AI (Cantonese)
Character: AI girl generated by WildCardX-XL-Fusion
Vocal Source: JENNIE – SOLO. Cover by Aiana (Korean)
Rapid Rhythm ⚡
Our avatars can maintain impressive synchronization with fast-paced rhythms, ensuring that even the quickest lyrics are matched with expressive and dynamic character animations.
Character: Leonardo Wilhelm DiCaprio
Vocal Source: EMINEM – GODZILLA (FT. JUICE WRLD) COVER
Character: KUN KUN
Vocal Source: Eminem – Rap God
Talking 🗣️
Interactive Conversations with Diverse Characters
This approach goes beyond just processing singing audio; it can also handle spoken words in multiple languages. Our system is capable of animating historical portraits, as well as 3D models and AI-generated content, infusing them with lifelike movement and realism.
Character: AI Chloe from Detroit Become Human
Vocal Source: Interview Clip
Character: Mona Lisa
Vocal Source: Shakespeare’s Monologue II As You Like It: Rosalind “Yes, one; and in this manner.”
Character: AI Ymir from AnyLora & Ymir Fritz Adult
Vocal Source: NieR: Automata
Cross-Actor Performance 🎭
Discover the remarkable capabilities of our framework, which allows for movie characters to deliver monologues or performances in diverse languages and styles. This feature expands the horizons of character representation across multilingual and multicultural contexts.
Character: Joaquin Rafael Phoenix – The Joker – 《Jocker 2019》
Vocal Source: 《The Dark Knight》 2008
Character: SongWen Zhang – QiQiang Gao – 《The Knockout》
Vocal Source: Online courses for legal exams
Character: AI girl generated by xxmix_9realisticSDXL
Vocal Source: Videos published by itsjuli4.
Source : original source







0 Comments